Bayesian linear regression
Linear regression 이란..?
어떤 Dataset 내에서의 어떤 특성을 선형적으로 표현하는 과정
$$
y = b_0 + b_i * x_i^T
$$
위와 같은 선형방정식에서 x(입력 값)와 y(출력값) 사이간의 관계를 찾는 과정이다. 그래서 주어진 Dataset에서 x_1의 변화에 따른 y값의 변화량과, 이 변화값들이 b_0, b_1에 끼치는 영향을 찾아야한다. 이때 y는 x_1의 변화에 따라 변하는 값이기때문에 y를 Dependent Variable(DV) x_1을 Independent Variable(IV) 이라고 한다. 그리고 DV와 IV의 관계 비율을 결정하는 b_i을 Coefficent하고 하며 Linear Regression의 초기값을 결정하는 b_0, Constant라고 한다.
???

위의 상황에서 학습 데이터의 지점에서 최소 오차( |y_i - y_i^| )를 보이는 b_1, b_0를 구해 특정 line을 구할수 있다. 이때 양수 오차와 음수 오차의 계산을 통일하기 위해 오차 값의 제곱을 ( |y_i - y_i^|^2 )을 이용한다. 이와 같이 오차를 최소화하는 방법을 최소 자승법이라고 한다.
$$
y(x,w)=w_0+\sum_{j=1}^{M-1} w_j\phi_j(x)
$$$$
\phi_j(x)=exp{-\frac{(x-\mu_j)}{2s^2}} :basis function
$$
Bayesian regression
위에서 언급한 Regression(최소 자승법)이 오차를 최소화하는 방법이라면 베이지안 회귀는 가능도를 최대화하는 것에 목적이 있다. 베이지안 회귀의 가장 기본적인 선형모델은 다음과 같다.
$$
y = \theta_1x + \theta_2+ \epsilon
$$
θ_1, θ_2: 모델의 파라미터, y: DV, x: IV, ε: 오차
=> x,y의 관측값을 통해 θ_1, θ_2를 추정하는 것이다.
여기서 "가능도(likehood)"란 확률의 개념과는 조금 다르다.
확률(possiability) : 관측값이 나올 확률
가능도(likehood) : 독립적으로 추출 가능한 모든 관측값 x_i가 확률 밀도에서 갖는 값의 곱
평균이 μ, 표준편차가 σ인 선형 모델에서 확률 분포는 다음과 같은 식을 가진다.
$$
x ~ N(\mu,\sigma^2)
$$$$
f(x;\mu,\sigma) = \frac{1}{{\sigma\sqrt{2\pi}}}exp(-\frac{(x-\mu)^2}{2\sigma^2})
$$
위 식을에서 정의된 가능도를 추산하는 식을 정리하면 다음과 같다.
$$
likehood = L(\theta_1, \theta_2;x,y)= \Pi_{i-1}^N \frac{1}{{\sigma\sqrt{2\pi}}}exp(-\frac{(y_i-{(\theta_1x_i+\theta_2)})^2}{2\sigma^2})
$$
한편 베이즈 추론은 우리가 직접 알 수 없는 것들에 대해서 추론할때 모델을 상정하고 관측이 추론으로 이어지는 과정을 담는 추론 방법이다. 베이즈 추론을 알기 위해서는 베이즈 추론이 되는 베이즈 정리를 알아야 한다. 베이즈 정리에서는 사건 A, B가 있을떄 사건 A와 B의 교집합의 확률에 관점을 부여한다.
$$
P(A|B)=P(A|B)P(B)=P(B|A)P(A)
$$
베이즈 정리는 이 관점을 "B라는 조건에서 A가 발생할 확률"로 보는 조건부확률로 표현한다.
$$
P(A|B)=\frac{P(A\cap B)}{P(B)}=\frac{P(A|B)P(B)}{P(B)}
$$
이를 모델 관점에서 보면 관측할 수 있는 것을 B, 추론해야할 것을 A로 둔다. 즉 B는 데이터 A는 추론을 시행하는 모델이다.
모델A 입장에서 살펴보면 추정을 시행하는 모델 A의 확률 분포 P(A)에서 관측값 B가 가능한 확률, 즉 관측값 B가 모델 A에서 가능한 "가능도"를 곱해줌으로서 B가 가능한 조건에서 A가 가능한 확률 P(A|B)로 모델의 확률 분포가 갱신되는 것이다.
이 개념을 수학적으로 풀려고 하는 데 아주 복잡하다..
정리하자면 베이즈 추론이란 관측값을 통해, 모델의 확률분포를 업데이트 하는 추론이다. 베이지안 추론을 통해 선형회귀의 최대 가능도 방법을 시행하면서 발생할 수 있는 과적합 문제를 피할수 있으며 훈련 데이터를 통해 모델의 복잡도를 결정할수 있다는 장점이 있다.
하지만 문제가 있다. 관측값 B를 관측하기 전인 P(A)를 사전 분포, 관측값이 반영된 확률분포 P(A|B)를 사후분포라고 했을때 확률분포에 반영되어야할 관측값의 수가 늘어난다면 사후분포를 탐색해야하는 공간이 지수함수 꼴로 늘어나기 때문에 이에 대응하기 위한 전략을 마련해야 한다.
과적합 문제( Overfitting) : 훈련 데이터의 오차를 모두 반영되어 일반성을 상실한 상태
???

사후분포 탐색전략 - 마르코프 체인 몬테카를로법(MCMC)
마르코프 체인은 어떤 상태가 바로 이전 상태의 결과에 영향을 받는 상황을 의미한다. 그리고 몬테카를로는 무작위 샘플링을 말하는 것이다. 즉, 이 둘을 합치면 어떤 상태가 무작위적이지만 이전 상황에 의존적으로 움직이는(전이되는) 상황 을 말한다.
그래서 MCMC는 특정 조건의 마르코프 체인이 정상 상태 분포(steady-state distribution)를 나타내며 ergodic하다는 점을 이용한다. 여기서 정상 상태 분포가 ergodic하게 만들 수 있는 특정 조건은 1. 전이 상태가 하나의 값으로 정착 되지 않을?조건 2. 전이가 주기성을 띄지 않을 조건을 말한다. 베이즈 추론에서 수많은 관측값으로부터 MCMC를 적용하기 위해서는 앞서 말한 조건을 만족하는 형태로 샘플링을 진행해야 할것이다.
그래서 제시된 MCMC 샘플링 방식은 임의의 랜덤한 관측값에서 시작하되 이전값이 다음값에 영향을 주도록 i번째 표본을 참고해, 다음 i+1번째 표본을 선발하는 방식을 사용한다. 놀랍게도 관측값이 많으면 많을수록 실제 뽑아낸 확률분포와 비슷하게 수렴하게 된다고 한다.
???

다만 여기서 "임의의 랜덤한 관측값에서 시작하되 이전값이 다음값에 영향을 주도록 i번째 표본을 참고해, 다음 i+1번째 표본을 선발하는 방식"의 실제적 방법론은 다양한 MCMC 구현 알고리즘이 존재한다.
구현 MCMC 알고리즘 : Metropolis-Hastings 알고리즘
마르코프 체인 : 어떤 인과적 상황에서 여러상태{x_1,x_2, ....}들이 존재할 수 있음을 가정할때, 특정상황 x_i에서 이외 다른 상황 x_j로 상태가 전이될 조건부확률의 확률 분포는 정해져있는, 그래서 폐쇄된 Steady-state diagram을 그릴 수 있는 정상 상태 분포를 나타낼 수 있는 상황을 말한다. 위에서는 임의의 관측값에서 시작해 의도적으로 특정 파라미터를 기준으로 다음 관측 표본을 선정하는 상황 자체를 마프코프 체인이라고 보는 것이다.
Ergodic : 전체 표본에 대한 통계적 평균과 시간적 평균, 혹은 랜덤한 부분 집합의 평균이 동일한 특성을 보이는 성질. 다시말해 부분 집합에 해당하는 표본의 특성이 전체 표본의 통계적 특성을 대표할 수 있음을 표현하는 성질이다.
그래서 마프로프 체인에서는 위에서 언급한 2가지 조건이 만족하도록 MCMC가 구현된다면 전체 모집단의 통계(여기서는 확률분포)를 반영한다는 것이 수학적으로 증명되어 이용하는 것이다.
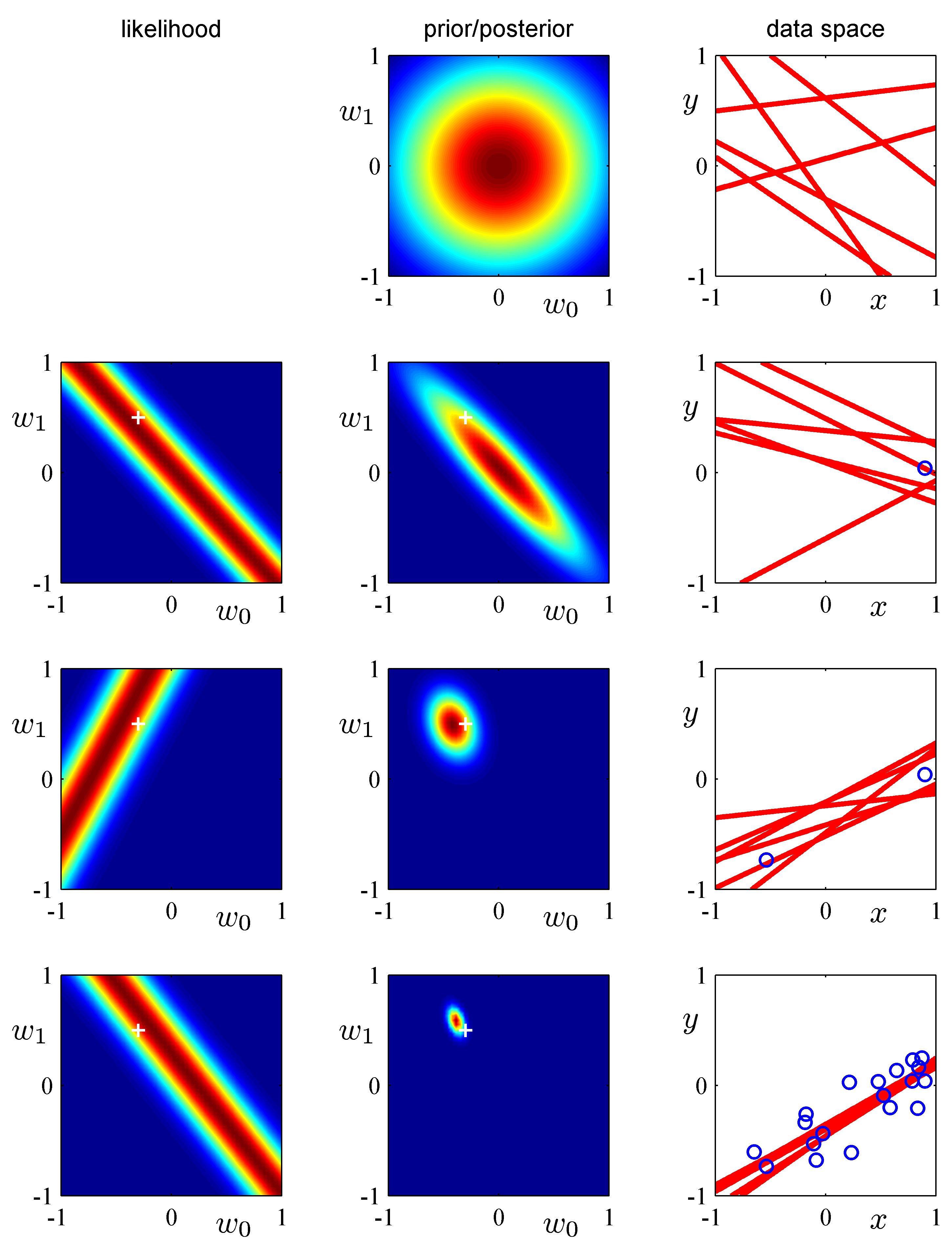
정리하자면 Bayesian regression 은 베이즈 정리를 기반으로 사전 확률 분포에서 MCMC기법에 의거, 선정된 관측값을 반영하여 사후 확률분포를 추산하는 방식으로 모든 관측값이 반영되었을 때 새로운 값 관측값(unobserved data) x에 대한 출력값 y를 확률 분포에 의거 결정할 수 있는 예측 분포 (Prodictive distribution) 를 만드는 모델이라고 할 수 있다.
Bayesian regression에서의 예측 분포(Predictive distribution)
unobserved data(y')에 대한 사전 예측 분포와 사후 예측분포는 다음과 같다. 여기서 사전예측분포는 사전 가능도 함수의 곱을 적분한 형태로 정의 된다. 이는 θ에 대한 가능도 함수의 평균이다. 사후예측분포는 새로운 관측결과 y와 확률 변수 y~의 관계가 독립이라 가정한다. 그래서 Unobserved data에 대한 가능도는 가능도와 Observed data의 곱으로 정의 된다. 왜라고 묻는다면 그 뒤에는 어려운 수학 수식들이 기다리고 있다.
- 사전 예측 분포
$$
p(\widetilde{y})=\int p(\widetilde{y},\theta)d\theta=\int p(\widetilde{y}|\theta)\times p(\theta) d\theta
$$
- 사후 예측 분포
$$
p(\widetilde{y}|y)=\int p(\widetilde{y},\theta|y)d\theta=\int p(\widetilde{y}|\theta,y)\times p(\theta|y) d\theta
$$
???
Bayesian logistic regression
logistic regression이란..?
회귀를 사용하여 요구되는 범주에 속할 확률을 0~1 사이의 값으로 예측하고 이 확률에 따라 더 가능성이 높은 범주에 속하는 편으로 분류해주는 지도학습 알고리즘이다. 선형회귀와 비교하자면 선형회귀는 +와 - 방향으로 무한히 뻗어 가나는데 이 경우 극단적인 표본에 있어서는 비현실적인 값(음수 확률)을 출력하게 된다. ???

로지스틱 회귀에서는 확률이 0과 1 사이의 값이 출력되는데 이 경우 아래 사진과 같은 극단에서 수렴하는 그래프를 그리게 된다.???

로지스틱 회귀의 확률 예측 단계
- 모든 속성(feature)들의 계수(coefficient)와 절편(intercept)을 0으로 초기화한다.
- 각 속성들의 값(value)에 계수(coefficient)를 곱해서?log-odds를 구한다.
- log-odds를?sigmoid 함수에 넣어서?[0,1]?범위의 확률을 구한다.
Log-Odds
선형회귀에서는 속성값(x)에 계수(coefficient)에 곱하고 절편(intercept)을 더해서 예측값을 구하는 방식이다. 로지스틱 회귀에서는 이와 예측값 대신에 log-odds를 구해야한다는 점에서 차이가 있다.
$$
Log-odds=log(\frac{P(event,occuring)}{P(event,not,occurring)})
$$
로지스틱 회귀에서는 선형회귀에서 처럼 예측값을 구하려면 dot product (내적)방식으로 log-odds를 구할수 있다.
각 속성들의 값이 포함된 행렬과 각 계수가 포함된 행렬은 다음과 같이 계산한다.
$$
z=b_0+b_1x_1+\cdots+b_nx_n
$$$$
\begin{bmatrix}b_0\b_1\b_2\\vdots\end{bmatrix} \begin{bmatrix}x_0x_1x_2\cdots\end{bmatrix} =b_0 x_0+b_1 x_1+b_2 x_2
$$
Sigmoid Function
로지스틱 회귀에서 확률을 0과 1사이의 커브 모양으로 나타나게 해주는 것이 Sigmod 함수이다.???

위에서 도출된 Log-odds를 sigmoid함수에 대이하여 0과 1사이의 값으로 변환해주는 것이다.
확인 결과 Bayesian logistic regression은 분류 모델에 해당해 본 과제에는 우선 관련사항이 없는것으로 판단된다.
'공부 학습' 카테고리의 다른 글
| 머신러닝 정리(종합) (0) | 2022.07.25 |
|---|---|
| Catboost 기본부터 알아보기 (0) | 2022.04.02 |
| 네트워크 CH4 - Network Layer 3 (0) | 2021.05.04 |
| 운영체제 CH7(10주차) (0) | 2021.05.04 |
| 네트워크 CH4 - Network Layer 2 (0) | 2021.04.28 |